Design a Job Scheduler
Overview
“Design a distributed job scheduler” is a common system-design interview question. It touches on several concepts related to a distributed environment. In this article, we shall learn about how to design a distributed job scheduler.
Functional Requirements
A task may be scheduled one time or multiple times as in a cron job by other microservices/services. For every task, a specific class can be made inheriting an interface, such that we can call that interface method later, on the worker nodes while executing the task. The results of executions of tasks will be stored and queryable.
Non-Functional Requirements
Scalability
Millions of jobs can be scheduled and executed in a day.
Durability
A job shouldn’t be lost and must persist.
Reliability
A job shouldn’t be dropped or performed later than scheduled.
Availability
It should be possible all the time to schedule and perform tasks. A task should be executed a minimum number of times (ideally one).
Domain Analysis
We first define a domain model that will be later transformed into a data model for Schema or a model for zooKeeper.
Job
It’s a task that has to be performed.
Properties
id, name, taskRunnerClass, priority, running, lastBeginTime, lastFinishTime, lastRunner, arguments (data)
Trigger
Tells when a task gets done. A job may have multiple triggers.
Many types of triggers are defined, such as oneTimeTrigger, cronTrigger, etc.
There will be properties, dependent on the type, such as id, type, beginTime, finishTime, oneTime, cronjob, interval, etc.
Executor
It’s a single node for task execution. It has properties such as id, lastHeartBeat, etc.
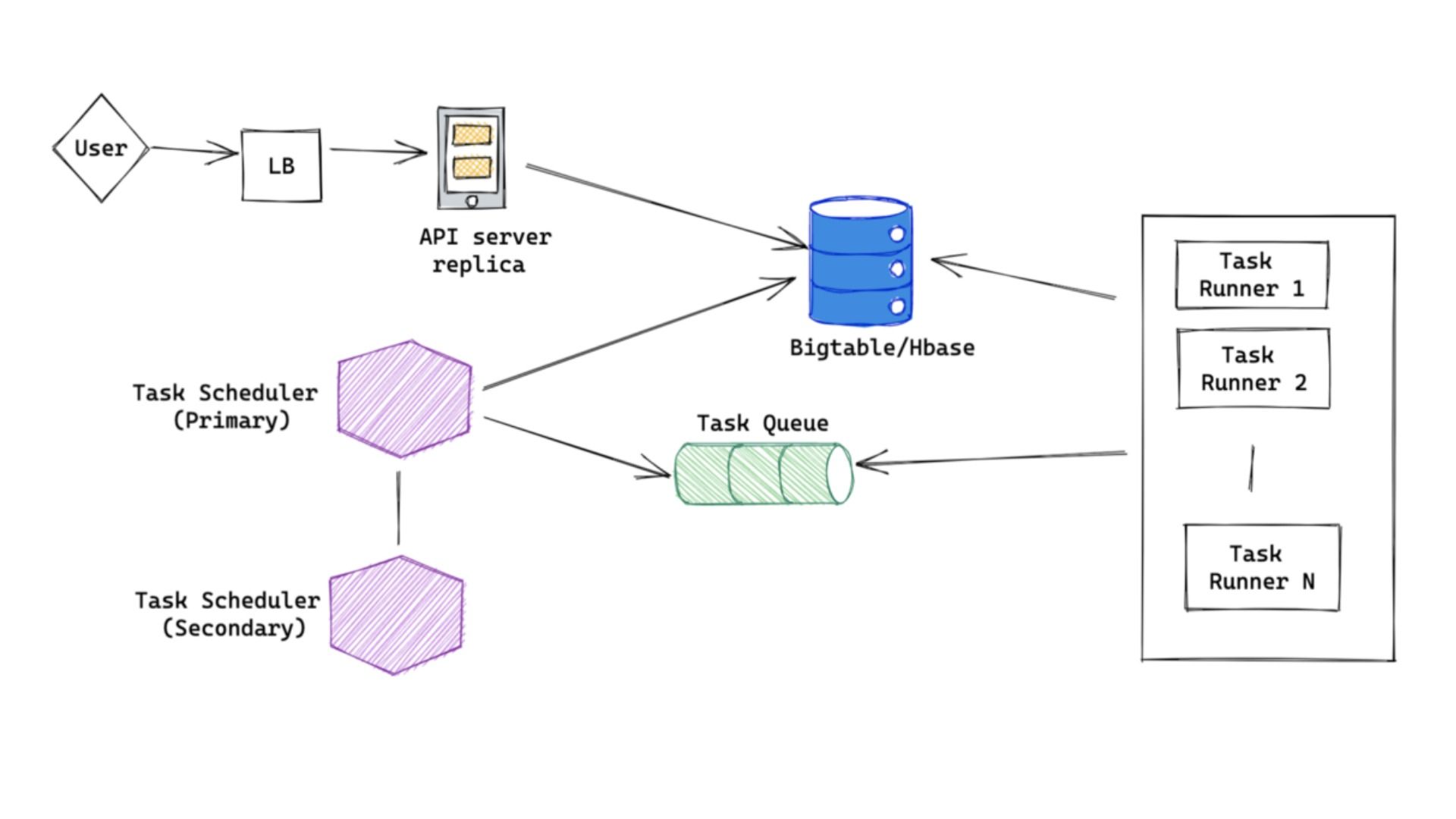
A High-Level Design

A microservice aiming at scheduling a task can transfer a message to the corresponding Kafka queue.
Job Scheduler Service
It will utilize the messages (demanding a task enqueueing). They (messages) generate a unique id, based on which they decide the database partition into which the task shall go. They create a task and trigger record as power the message in the corresponding database partition.
RDBMS
It would be suitable as we may later require its ACID properties, especially transactions. We will adequately shard the database several shards to distribute the data and load. We will use the master-slave/active-passive replication for every partition in a semi-synchronous manner. One follower/slave will synchronously follow while the others receive the replication stream asynchronously. This way, we ensure that a minimum of one slave holds updated data in case the master fails, followed by that slave being promoted to the new leader.
Job Executor Service
- On startup, it gets the database partitioning information from zooKeeper and the partition assignment between database partitions and other instances.
- It chooses a database partition having the smallest count of executors mapped to balance out the count of executors that execute tasks for every different database partition.
- It will store/transfer the partition assignment to zooKeeper and uniformly send heartbeats to zooKeeper.
- It fetches info from the database partition and resists other executor instances mapped to the very same database partition for tasks the execution of which is due. The resistance uses row locks, which require transactional properties.
- An executor node performs a task after it has updated the task record in the database by flagging it as “running”, storing the “beginTime” and itself as the executor node, etc.
- If an executor node fails, other nodes that are assigned the same partition can use the zooKeeper and heartBeating to detect the failure and then hunt down all the tasks that were being executed by the failed node, thus flagging flag=”running” and lastExecutor=”failed node” and can resist those tasks to perform them.
- Eventually after having performed a task, we transfer a message to another Kafka queue.
Result Handler Service
It utilizes the messages and stores the result of the execution in a non-relational database such as MongoDB, Cassandra, etc. The eventual consistency is fine as it is not pivotal if a result with some delay is observed.
ZooKeeper, Coordination Service
It stores the information mentioned above. We may load the database partitioning information from a configuration file/service into ZooKeeper.
Message Queues
We use message queues for:
- Independently scaling the nodes and producer/consumer.
- We isolate the producer and consumer from each other.
- The latency for the producer must be low.
- If a consumer node crashes, some other node can process the message, which otherwise would be lost.
- We can limit the count of messages that are processed by consumers.
- Ordering of messages is done by Kafka.