Complete Guide To Decision Tree Algorithms for Beginners /w Examples

Methods like decision trees, random forest, gradient boosting are being popularly used in all kinds of data science problems. It’s important that every analyst (even freshers) learn these algorithms and use them for modeling purposes.
Decision trees provide the foundation for more advanced ensemble methods such as bagging, random forests, and gradient boosting. Decision trees are widely used in many applications for predictive modeling, including both classification and regression.
Let’s start with the basics first...
What is a Decision Tree?
Decision Trees are a class of very powerful Machine Learning models cable of achieving high accuracy in many tasks while being highly interpretable. What makes decision trees special in the realm of ML models is really their clarity of information representation.
The “knowledge” learned by a decision tree through training is directly formulated into a hierarchical structure. A tree or graph-like structure is constructed to display algorithms and reach the possible consequences of a problem statement.
This is a predictive modeling tool that is constructed by an algorithmic approach in a method such that the data set is split based on various conditions. They are popular because the final model is so easy to understand by practitioners and domain experts alike.
The final decision tree can explain exactly why a specific prediction was made, making it very attractive for operational use. They also have a ton of applications in the real world.
Types of Decision Trees
1. Categorical Variable Decision Trees
This is where the algorithm has a categorical target variable. For example, consider you are asked to predict the relative price of a computer as one of three categories: low, medium, or high. Features could include monitor type, speaker quality, RAM, and SSD. The decision tree will learn from these features and after passing each data point through each node, it will end up at a leaf node of one of the three categorical targets low, medium, or high.
2. Continuous Variable Decision Trees
In this case the features input to the decision tree (e.g. qualities of a house) will be used to predict a continuous output (e.g. the price of that house).
DTs are composed of nodes, branches, and leaves. Each node represents an attribute (or feature), each branch represents a rule (or decision), and each leaf represents an outcome. The depth of a Tree is defined by the number of levels, not including the root node.
Real Life Example
(Source: A Guide to Decision Trees for Machine Learning and Data Science)
You’ve probably used a decision tree before making a decision in your own life. Take for example the decision about what activity you should do this weekend. It might depend on whether or not you feel like going out with your friends or spending the weekend alone; in both cases, your decision also depends on the weather. If it’s sunny and your friends are available, you may want to play soccer. If it ends up raining you’ll go to a movie. And if your friends don’t show up at all, well then you like playing video games no matter what the weather is like!
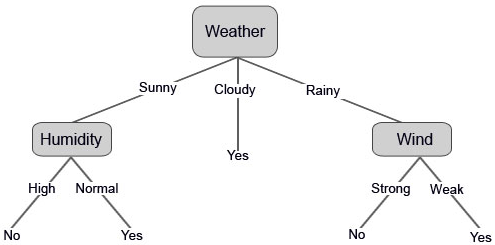
This is a clear example of a real-life decision tree. We’ve built a tree to model a set of sequential, hierarchical decisions that ultimately lead to some final results. Notice that we’ve also chosen our decisions to be quite “high-level” in order to keep the tree small. For example, what if we set up many possible options for the weather such as 25 degrees sunny, 25 degrees raining, 26 degrees sunny, 26 degrees raining, 27 degrees sunny…. etc, our tree would be huge! The exact temperature really isn’t too relevant, we just want to know whether it’s OK to be outside or not.
The concept is the same for decision trees in Machine Learning. The decisions will be selected such that the tree is as small as possible while aiming for high classification/regression accuracy.
Decision Trees are also used in the following sectors:
- Business Management
- Customer Relationship Management
- Fraudulent Statement Detection
- Energy Consumption
- Healthcare Management
- Fault Diagnosis
Advantages & Disadvantages of Decision Trees
Advantages:
- Compared to other algorithms, they take very little time in processing data
- It is easy & intuitive to understand or explain to others
- Decision trees cope up with both continuous variables and categorical variables
Disadvantages:
- Any small change in data can lead to a huge change in the decision tree which could further lead to instability
- One output attribute is restricted for the Decision Tree
- Decision Tree is an unstable classifier
Conclusion
Decision tree algorithms are probably one of the most useful supervised learning algorithms out there. As a fresher, it is important for you to learn this, among other algorithms, to use them for modeling purposes in data science problems. Now that you're thorough with the basics, get to learning and exploring more of these algorithms.
Data science & Machine learning is a very vast sector. If you want to learn more about it then enroll in Board Infinity's Machine Learning and Artificial Intelligence Course and get access to premium content. Learn with 1:1 help from industry experts and get certified!