Machine Learning in Python: Supervised vs Unsupervised Learning

Supervised & Unsupervised learning systems are two major categories of teaching a machine learning system to take self-governed decisions. Now, before dwelling deep into the nitty-gritty of supervised learning; it is important to understand the concept of classification (or labeling) in machine language.
1. What is classification in machine learning?
Classification (also at times, referred to as labeling) is an approach using which the ML algorithm learns from a well-identified and tagged dataset. The tagging or labeling which is already present in the training dataset is then used to classify new input variables or observations. For example – a training data set wherein a particular object has a defined color of ‘red’ is stated as a classified data set. An apple is ‘red’ in color. Now, once the ML system learns from this; any other fruit which is red in color would be confirmed as an ‘Apple’.
This concept of classification; wherein the machine learning system is extrinsically taught on how to behave is the core principle of supervised learning systems.
2. Supervised learning vs. Unsupervised learning
Supervised and unsupervised learning systems are two broad categories of ML systems – depending largely on the nature of the data used to train the systems. Supervised learning, as the name suggests, happens in a ‘supervised or controlled’ environment wherein the data used to train the data is richly categorized and tagged. This categorization would be learned by the machine and applied when a new set of data would be provided as an input to the system.
A perfect analogy of a supervised learning system could be similar to impart a series of question & answers to a system as a training mechanism; which the system would refer to answer future questions which may come their way.
Unsupervised learning mechanisms, on the other hand, don’t train themselves on categorized or labeled data. Hence, in this method, there is no distinct logic to categorize a particular object. Rather, they render the response basis similarities, trends & patterns in the input object.
3. Supervised learning algorithms using Python
Under the category of ‘supervised learning, there are multiple algorithms that can be implemented using Python.
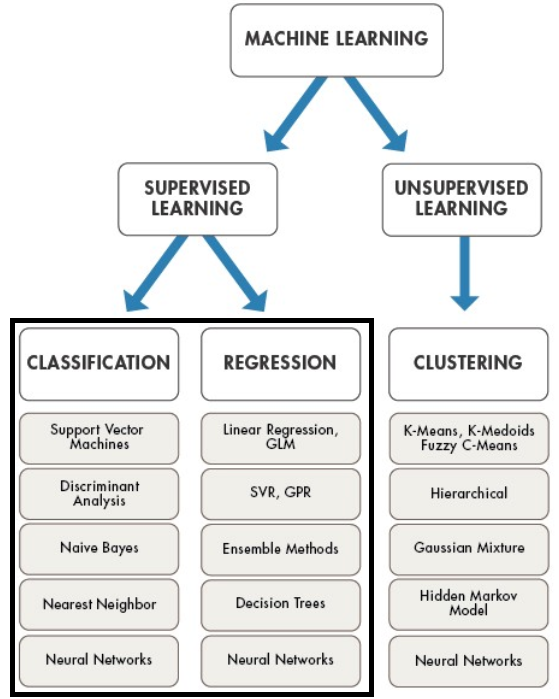
As shown in the figure, ‘classification’ and ‘regression’ are the two major implementations of supervised learning. The key difference between the two is that while the output of a classification algorithm is a ‘category’; the output of regression is a ‘real value’.
As a next step, go ahead and check out the Video on Unsupervised Learning and Clustering: