Fundas of Pandas

Hey there rising data scientist!
Looking for a quick tutorial before your Interview or for your college viva? Worry not, we have got you covered. In this article we will look over the Fundas of Pandas you must know about in order to ace your interviews or viva. If you are new to the world of data science or python programming this article will give you a brief overview of the popular data science library, Pandas.
1. What Is Pandas?
Pandas is a fast, powerful, flexible, and easy to use open-source data analysis and manipulation tool, built on top of the Python programming language. Simply put, Pandas is used for creating, manipulating, and querying data from a data frame.
2. What Kind Of Data Does Pandas Handle?
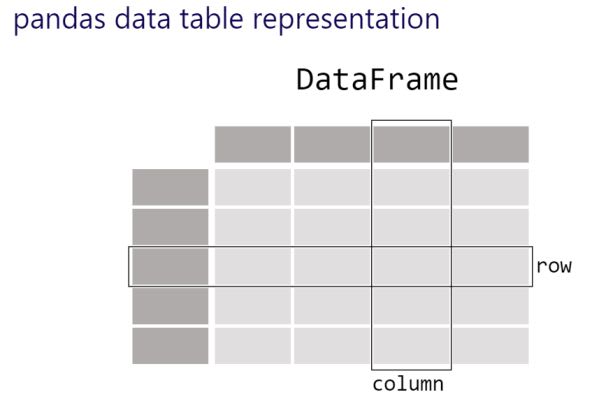
- A table of data is stored as a Pandas Dataframe
- Each individual column in a Data Frame is a Series
- Each individual row in a Data Frame is a record
- You can do things by applying a method to a DataFrame or Series
3. How To Read Data In Pandas
Step 1. Import Pandas
First, you will need to import the pandas library to your code, and since it can get tedious at times to write it down fully, we will import pandas as pd alias. This is an industry-standard practice

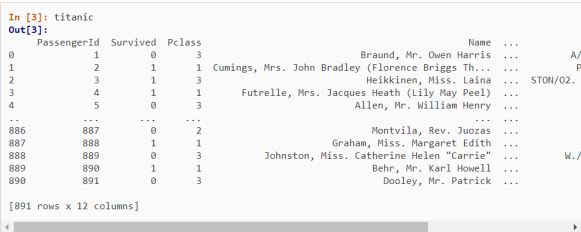
Step 2. Read Data
In most cases data frames are retrieved from a csv file, for that we will use pd.read_csv() function, similarly you can use pd.read_excel(), pd.read_sql() for reading data from other file formats. To know more click here

4. Primer Functions
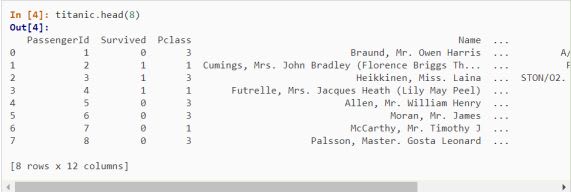
head()
The head function is used to display the first n rows of a data frame, if no argument is provided it will show 5 rows by default.
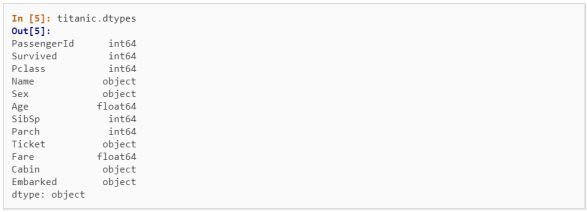
dtypes
This function is used to display the data types of every column.
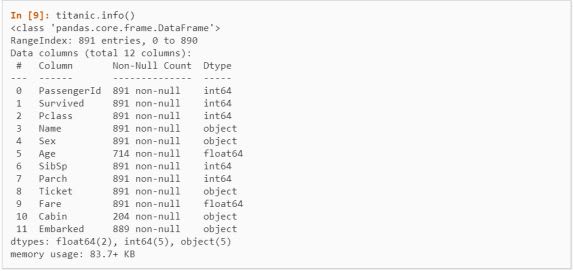
info()
This function provides us with the technical summary of a data frame, it provides us with the number of entities involved, their data types, and non-null values.
5. Subset of a Data Frame
A subset refers to a selected set of rows and columns from a larger data frame, subsetting the data is an essential part of the data cleaning process, as having irrelevant data while modeling can affect the end outcome. Embedding all the relevant syntax here is beyond the scope of this blog, for more info click here
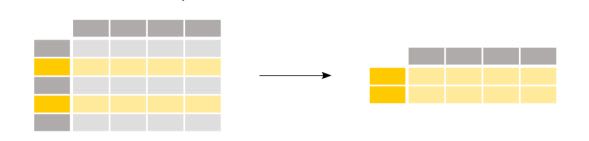
subsetting can be done in 3 ways i.e.
1. Rows only
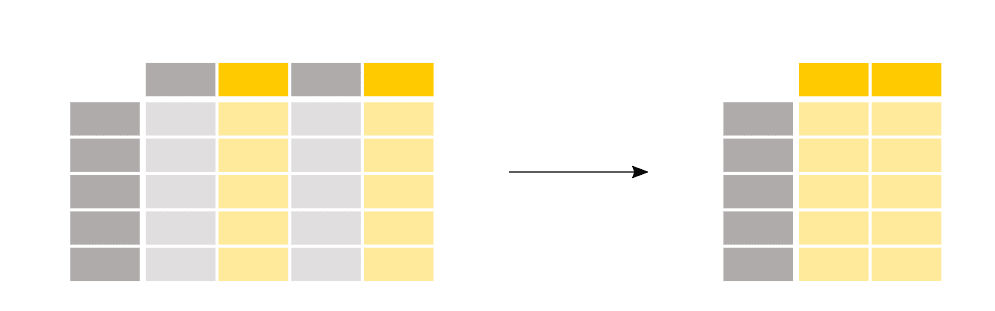
2. Columns only
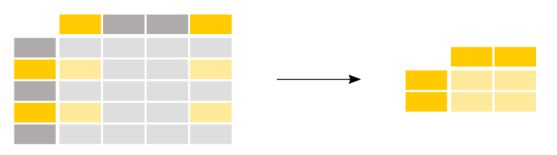
3. Both
6. Basic Statistical functions
mean()
This can be used to calculate the mean of single or multiple columns depending on the input.

median()
This can be used to calculate the median of single or multiple columns depending on the input.

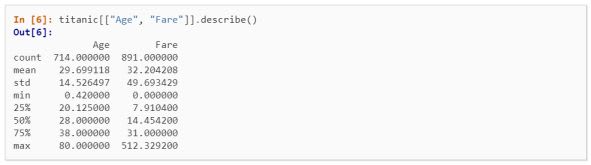
describe()
It is a very powerful and productive function, it provides multiple data points like mean, count, min, max, percentile, and standard deviation for the given columns.
agg()
The drawback of a describe function is that it only provides fixed matrices, but if you want a custom set of matrices then agg() function is the way to go.

groupby()
This can be used to group a particular set of entities in the data frame

That's it for now, we will discuss the advanced features of pandas in the coming articles. Hope this gave you a good overview of pandas and its most used functions.
Note - This article is a crisp version of tutorials and documentation on the official pandas website.
If you're interested in learning Python, enroll in Board Infinity's 1:1 Live Classes on Python and go from being a beginner to an expert with the help of top industry experts!