NoSQL Databases: What are They?
Introduction
NoSQL databases: what are they?
NoSQL databases are designed specifically for particular data types and offer adaptable schemas for creating cutting-edge applications. NoSQL databases are well known for their simplicity of construction, usefulness, and scalability. Resources are provided on this page to assist you in learning more about NoSQL databases and getting started.
What is the Operation of a NoSQL (nonrelational) Database?
For organizing and accessing data, NoSQL databases employ a number of different data models. By easing some of the data consistency constraints of traditional databases, these databases are specifically tailored for applications that need enormous data volumes, low latency, and flexible data models.
Take modeling the schema for a straightforward book database as an example:
- In a relational database, a book record is frequently broken down (or "normalized") and stored in different tables, with primary and foreign key constraints defining relationships. This example has columns for ISBN, Book Title, and Edition Number in the Books table, AuthorID and Author Name in the Authors table, and AuthorID and ISBN in the Author-ISBN table. In order to enable the database to enforce referential integrity between database tables, the relational model was created. It is normalized to reduce redundancy and is generally storage-optimized.
- A book record is typically stored as a JSON document in a NoSQL database. Each book has a single document containing attributes for the item, ISBN, Book Title, Edition Number, Author Name, and AuthorID. This paradigm optimizes data for both horizontal scalability and intuitive development.
The Benefits of using a NoSQL Database:
Many contemporary applications, including mobile, online, and gaming, require flexible, scalable, high-performance, and highly functional databases to deliver excellent user experiences. NoSQL databases are a fantastic fit for these applications.
- Flexibility: Flexible schemas are typically offered by NoSQL databases, allowing for quicker and iterative development. NoSQL databases are the best choice for semi-structured and unstructured data because of their adaptable data model.
- Scalability: NoSQL databases are typically built to grow out by utilizing distributed hardware clusters rather than scaling up by introducing more pricey and reliable servers. Some cloud service providers perform these tasks invisibly as a fully managed service.
- High performance: When compared to attempting to carry out equivalent functions using relational databases, NoSQL databases are designed for certain data models and access patterns, enabling higher performance.
- Highly functional: NoSQL databases offer highly functional APIs and data types that are created specifically for each of their individual data models.
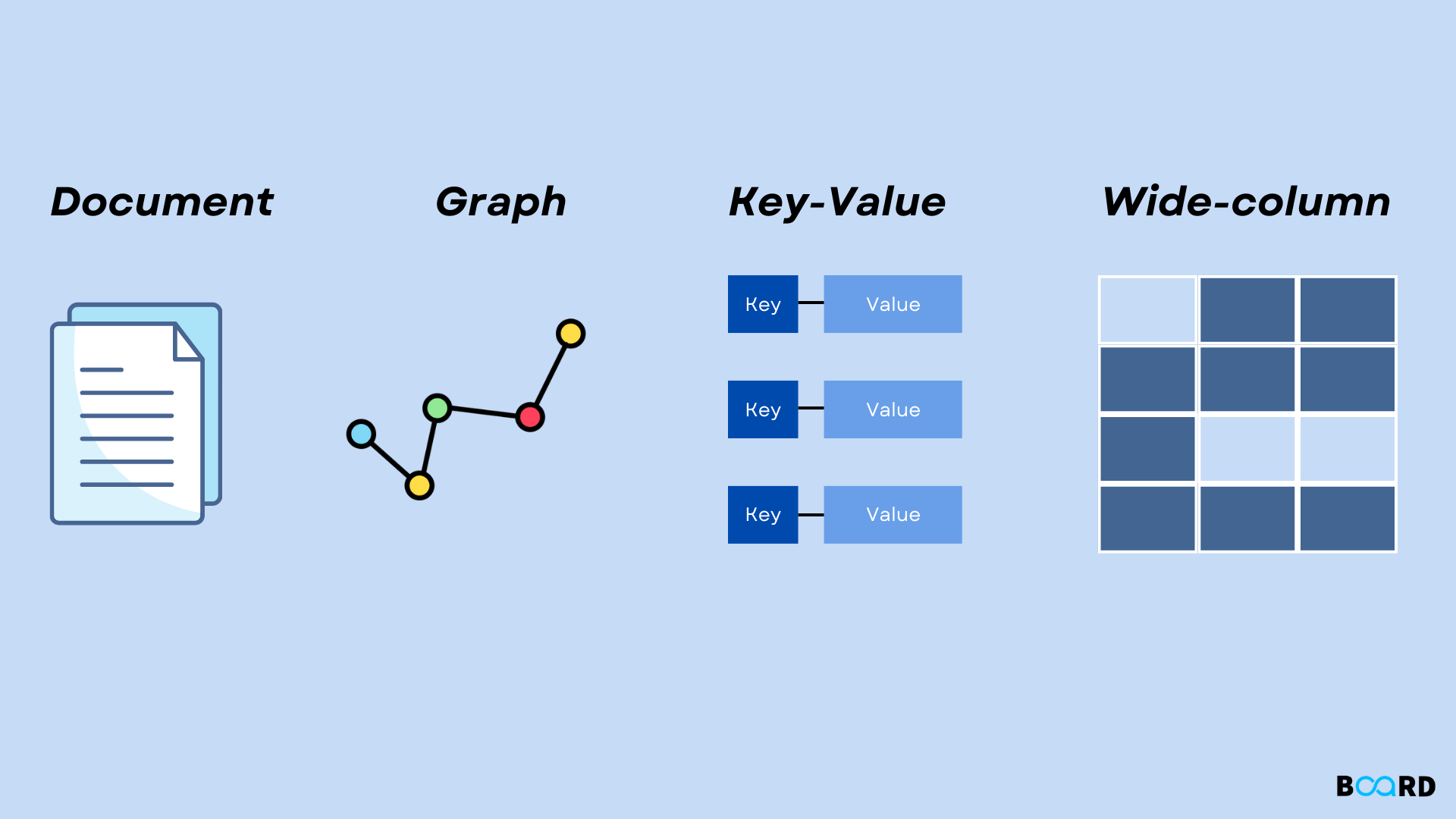
NoSQL Database Types:
- Key-value: Key-value databases enable horizontal scaling at scales that other types of databases are unable to accomplish. They are also extremely partitionable. The key-value data paradigm works particularly well for use cases like gaming, ad tech, and IoT. For whatever size of demand, Amazon DynamoDB is built to consistently deliver single-digit millisecond latency. The Snapchat Stories feature, which contains Snapchat's highest storage write workload, was switched to DynamoDB in large part due to its constant performance.
- Document: Data is frequently represented in application code as an object or a document that resembles JSON because it provides developers with an effective and simple data model. By employing the same document model format as their application code, document databases make it simpler for developers to store and query data in a database. Documents and document databases are flexible, semistructured, and hierarchical in design, allowing them to change to meet the demands of applications. The document model is effective with content management systems, user profiles, and catalogs when each document is distinct and changes over time. Popular document databases like MongoDB and Amazon DocumentDB (which are compatible with MongoDB) offer robust and user-friendly APIs for flexible and iterative development.
- Graph: A graph database is used to facilitate the development and operation of programs that operate on densely connected datasets. Social networking, recommendation engines, fraud detection, and knowledge graphs are examples of common use cases for a graph database. A fully-managed graph database service is Amazon Neptune. Neptune offers the choice of two graph APIs: TinkerPop and RDF/SPARQL, and supports both the Property Graph model and the Resource Description Framework (RDF). Neo4j and Giraph are two well-known graph databases.
- In-memory: Leaderboards, session storage, and real-time analytics are a few examples of in-memory use cases in gaming and ad-tech systems that call for microsecond reaction times and are susceptible to sudden surges in traffic. A resilient in-memory database service that supports Redis and offers microsecond read latency, single-digit millisecond write latency, and Multi-AZ durability is called Amazon MemoryDB for Redis. You may use MemoryDB as your main database for contemporary, microservices apps because it was specifically designed to give incredibly fast speed and durability. For low-latency, high-throughput workloads, Amazon ElastiCache is a fully managed, in-memory caching solution that is compatible with both Redis and Memcached. In-memory data stores are preferred over disk-based data stores by clients like Tinder that need real-time reactions from their services.
- Search: Many programs produce logs that aid programmers in problem-solving. By indexing, aggregating, and searching semi-structured logs and metrics, Amazon OpenSearch Service is designed specifically for offering near-real-time visualizations and analytics of machine-generated data. For use cases involving full-text search, Amazon OpenSearch Service is also a potent, high-performance search engine. For a range of mission-critical use cases, including operational monitoring and troubleshooting, distributed application stack tracing, and price optimization, Expedia uses more than 150 Amazon OpenSearch Service domains, 30 TB of data, and 30 billion documents.
Mark Lesson Complete (NoSQL Databases: What are They?)
Mark Complete
Bookmark