A Quick Guide to Relational Model in DBMS
The Relational Model in DBMS is the foundation of a majority of the current database environments. Proposed by Edgar F. Codd in the 1970s it is a revolutionized technique to store data. In this blog, all details concerning this model’s fundamentals, structure, functions, and strengths are explained.
Introduction to the Relational Model in DBMS
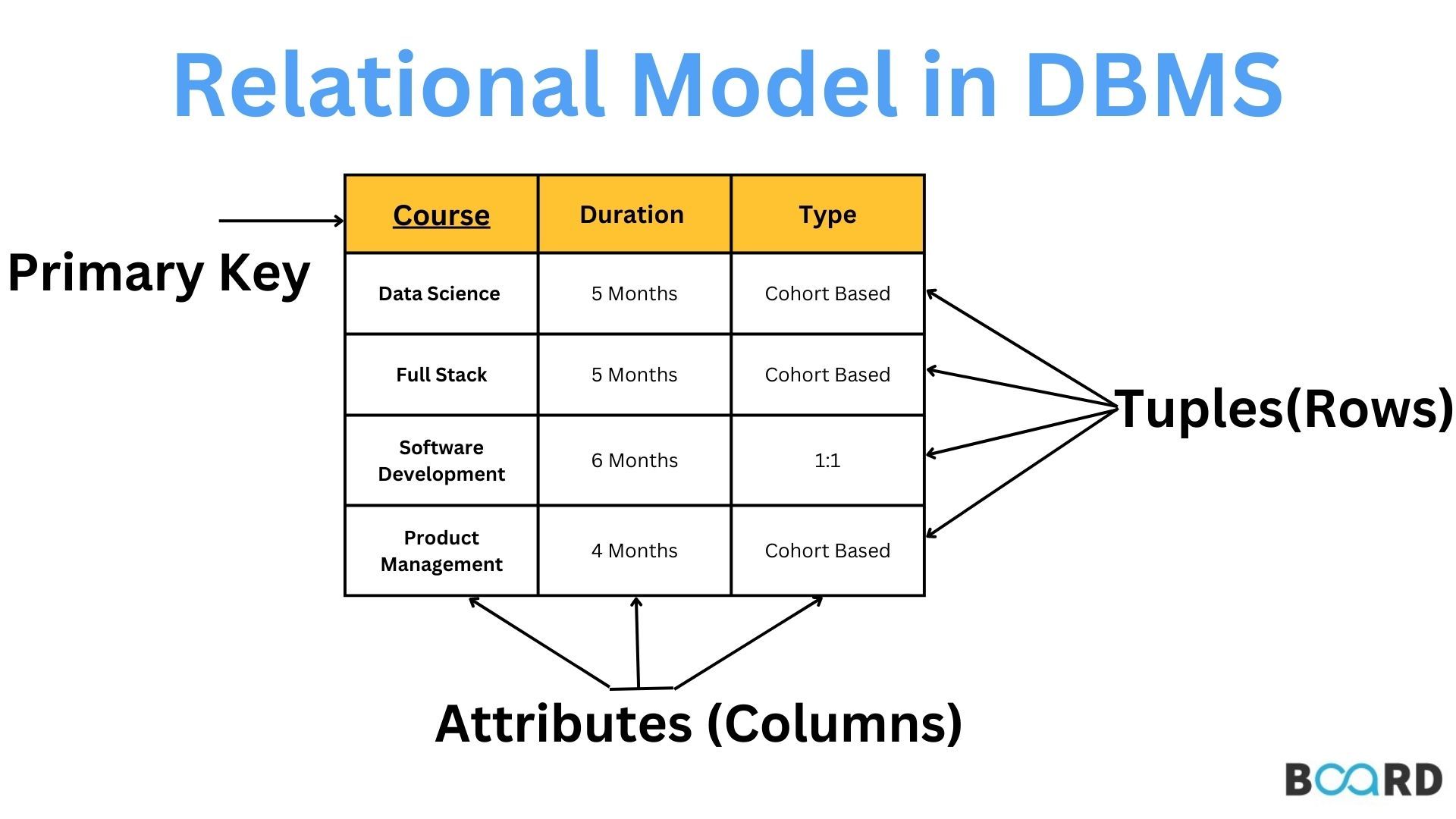
The Relational Model in DBMS stores information in a series of relations or tables. These tables are made of rows or tuples and too many columns or attributes. The subtyping shown above makes it easy to map to real-world objects and the design of object relationships.
Why is it Called a "Relational" Model?
The term “relational” relates to relations, which are more or less similar to tables in the structure of relational database. Unlike the hierarchical or network model, the relational model does not have fixed paths and utilization of languages such as SQL.
Characteristics of the Relational Model
- Simple Structure: Data is kept in the form of tables.
- Flexibility: As data is stored in a table, the structure can be easily changed when necessary.
- Data Independence: It shall also be noted that modifications in storage do not impact the logical schema.
Core Concepts of the Relational Model in DBMS
✅Relation
A relation is equal to a table in a database. It is a set of rows) involving attributes (columns) with the same structure.
Example of a relation: Student
| StudentID | Name | Age | Major |
|---|---|---|---|
| 1 | Alice | 20 | Computer Science |
| 2 | Bob | 22 | Mathematics |
| 3 | Charlie | 21 | Physics |
✅Tuple
A tuple denotes a record in a relation. In the "Student" relation, each row is a tuple:
- Tuple 1: (1, Alice, 20, Computer Science)
- Tuple 2: (2, Bob, 22, Mathematics)
✅Attribute
An attribute is also described as a variable that describes or defines the entity being analyzed. In the "Student" relation, the attributes are:
- StudentID
- Name
- Age
- Major
✅Domain
Specific allowable values are given by the domain of an attribute, which is a part of a structure. For example:
- The possible values in the domain of the “Age” attribute could be integer numbers from 0 to 150.
- The domain of the “Major” attribute could be for instance: [“Physics”, “Mathematics”, etc].
✅Relation Schema
The obligatory elements of a relation schema are the attributes of the relation and the domain of these attributes.
Student(StudentID: Integer, Name: String, Age: Integer, Major: String)
This schema specifies that:
StudentIDis an integer.Nameis a string.Ageis an integer.Majoris a string.
Relation Instance
A relation instance is data currently existing in a relation's context. It may change every time tuples are either inserted, modified, or deleted from the relation.
Key Elements of a Relation
✅ Columns (Attributes)
Attributes happen to be the vertical aspect of a table. Each attribute has:
- A Name: The name signifies the column sum up or gives a brief description of the data stored in it.
- A Domain: It limits the kind of data that it can handle.
✅ Rows (Tuples)
A tuple can be defined in a database field as a group of entries that is a horizontal part of a table. Each tuple holds a number of values and applies to the given attributes, which describes a single data entity
✅ Primary Key
The primary key is an attribute by itself or a set of attributes that define each record in a relation. For instance, StudentID in the “Student” category has been designed in such a way that no two students will share the same student ID.
✅ Foreign Key
The Conventional definition of a foreign key is an attribute in one relation, used to point to the primary key of another relation. For example:
- As for the StudentID, it can be worked as a foreign key where there is a “Courses” table; thus the relation between the “Courses” table and the “Student” table can be created.
Example with Keys:
Student Table
| StudentID | Name | Age | Major |
|---|---|---|---|
| 1 | Alice | 20 | CS |
| 2 | Bob | 22 | Math |
Courses Table
| CourseID | StudentID | CourseName |
|---|---|---|
| 101 | 1 | Databases |
| 102 | 2 | Calculus |
Here:
- StudentID in the “Courses” table is a foreign key that refers to the primary key in the “Student” table.
Keys in the Relational Model
Keys are used in order to have consistency as well as guarantee the uniqueness of records. Let's explore their types in detail:
✅ Super Key
Super key means a set of attributes that allows the identification of a unique tuple.
{StudentID}or{StudentID, Name}in the "Student" table.
✅ Candidate Key
A candidate key is a minimal super key or it is a part of a super key that contains the attributes on which users are expected to perform searches. Its extent refers to the smallest number of attributes that have the ability to distinguish between tuples.
{StudentID}is a candidate key, but{StudentID, Name}is not, as "Name" is redundant.
✅ Primary Key
A primary key is a candidate key selected to identify tuples in a database. It cannot have null values, meaning that for every record being stored the value of the KEY attribute must be filled.
✅ Foreign Key
A foreign key is used to link two tables where it forms the basis of relation with the primary key of another table.
Integrity Constraints
All integrity constraints bear the sub-title ‘The integrity rules are constraints…’ and ensure the correctness and consistency of data.
✅ Domain Constraint
It ensures attribute value lies within a defined range or set of characteristics. For example:
- The “Age” attribute should only be an integer between 0 and 150.
✅ Entity Integrity
Check whether the primary key is unique and whether it is allowed to be null. This ensures that when we have put every related tuple in a table, each of them has a unique identifier.
✅ Referential Integrity
It Reaffirms in a table that the foreign keys used represent actual primary keys in another table. For example:
- It means if there is not the StudentID 999 in the “Student” table, then, the Courses table cannot have a value as 999 of the StudentID.
Relational Algebra and Operations
It was found that relational algebra and operations play a significant role in the database management process. Relational Algebra offers a formal model of operation and indeed of querying.
✅ Selection (σ)
Returns only those records for which some specified condition is met.
- Example: Retrieve students older than 20.
σ(Age > 20)(Student)
✅ Projection (π)
Select specific columns.
- Example: Retrieve the names and majors of students.
π(Name, Major)(Student)
✅ Union (∪)
This combines the rows of two relations with the same schema.
- Example: Join two student tables for two different departments of the same organization.
✅ Intersection (∩)
Locates all the rowesses, the common rows between two relations Of two matrices.
✅ Difference (-)
Identifies those rows in A relation that does not exist in another relation.
✅Join (⋈)
Joins two relations which are related by some attribute.
Advantages of the Relational Model in DBMS
The relational model in DBMS has been proven to have many merits that have made it last for quite some time. Now let’s try to understand what makes it one of the most used models to date for database management.
- Ease of Use
- The tabular model we see in the relational data model in DBMS directly relates to the real world in terms of its entities and properties.
- Even the casual user with little program coding experience can format the data into tables.
Example:
A Customer table:
| CustomerID | Name | Phone | |
|---|---|---|---|
| 101 | John Doe | john@example.com | 1234567890 |
In this context, any non-technical computer user can easily learn that each row records a customer with certain characteristics which include Name and Email.
Data Independence
The relational data model in DBMS achieves logical and physical data independence:
- Logical Data Independence: Updates in the logical schema such as the creation of an additional attribute do not impact how the application programs.
- Physical Data Independence: Modifications of the patterns of storing the data or the manner in which it is indexed does not affect the manner in which the data is used.
Real-World Impact:
For example, moving data from a local server to the cloud does not imply a change in the application’s database tiers.
Flexibility
The relational data model in DBMS supports dynamic querying using SQL, allowing users to:
- Restored single data fragments.
- Join multiple tables.
- Group and aggregate data.
Example:
You can query a database to find:
- People who ordered a product from your firm in the last month.
- Total sales accrued directly from a particular item of stock.
SQL makes these queries simple:
SELECT CustomerID, SUM(OrderAmount)
FROM Orders
WHERE OrderDate >= '2023-11-01'
GROUP BY CustomerID;
Scalability
The structure of relational databases is designed to handle:
- Large volumes of data.
- Multiple users, working simultaneously with the same or different data.
Scalability Enhancements:
- Horizontal scalability of OLAP databases through database partitioning.
- For quicker access to the data; indexing.
Security
Relational databases offer robust security features, such as:
- Role-based access control: Limit based on the roles of the end users.
- Encryption: Preserve certain figures such as credit card numbers.
- Auditing: Track for change for compliance purposes.
Mark Lesson Complete (A Quick Guide to Relational Model in DBMS)
Mark Complete
Bookmark