Deep Understanding of Distributed Database in DBMS

What is a Distributed Database in DBMS?
The concept of distributing incoming requests among multiple machines and resources is very popular in Computer Science. It is found almost everywhere like Operating Systems and Networking. In Database management also, the concept of Distributed Database is found in which a database is distributed among multiple host machines. In this article, we will discuss the Distributed Database in DBMS and why we need it.
Distributed Database Definition
A Distributed Database is a database that is spread over multiple computers over a network. This means that the data or files are stored in multiple databases but still, they can be simultaneously accessed and modified via the network.
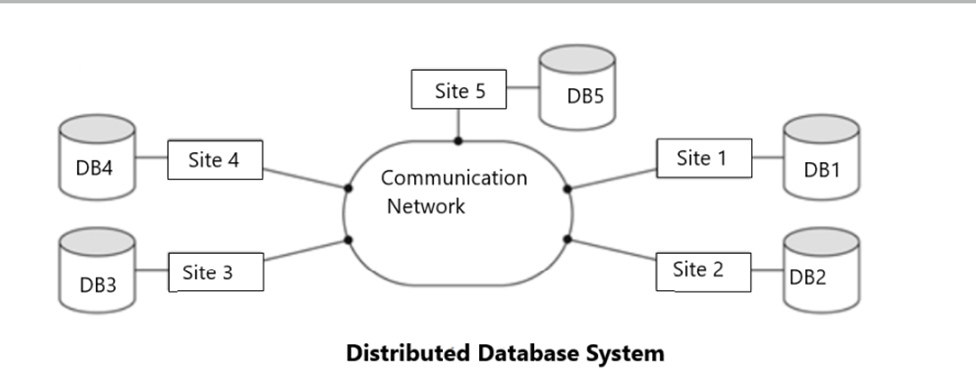
The databases which are located on multiple computers do not share any physical components, which means that they are loosely coupled. An important point about the Distributed Database is that it doesn’t appear to be multiple databases. For a user, it appears as a single database. The following diagram shows a simple Distributed Database in DBMS (DDBMS).
Types of Distributed Database Systems
After knowing what a Distributed Database in DBMS is, let’s see its types. There are two types of DDBMS- Homogeneous and Heterogeneous Distributed Systems which are discussed below:

Homogeneous Distributed Databases
A Homogeneous Distributed Database in DBMS involves multiple sites that use identical DBMS and operating systems. It's a network of identical databases. Each site or computer is aware of other sites and cooperates to perform the transactions.
Heterogeneous Distributed Databases
In a heterogeneous distributed database, different sites have different Operating Systems, Schemas, Data Models, and DBMS. This type of system can be formed using the combination of various types of DBMSs like Relational, Network, Hierarchical or Object-Oriented. Query processing is complex due to dissimilar schemas. Also, a site may not be aware of other sites and there is limited cooperation in processing user requests.
Design Strategies for Distributed Database in DBMS
The design of the Distributed Database refers to how data can be distributed over multiple computers. It can be broadly divided into the following categories:
Data Replication
Replication refers to the process of storing multiple copies of single data at different sites. Using Replication, multiple copies of the data are stored at selected sites of the system. Replication increases the fault tolerance of the system. But, it also increases the overhead of constant data updation at different sites to maintain data consistency. Data Replication in Distributed database can be done in two ways:
- Full Replication: In this replication, one copy of all the database tables is stored at each site of the Distributed Database System.
- Partial Replication: In this replication, copies of tables or portions of tables are stored at different sites of the system.
Data Fragmentation
In this design, a table is divided into two or more pieces referred to as fragments or partitions, and each fragment can be stored at different sites. This strategy is used because the need of accessing the entire data of a site seldomly happens, so it is better to store a part of the data at a given site.
The fragmentation of data should be done in such a way that partitions can be recombined to form the original table without any loss of data. This technique eliminates data redundancy as there are no copies of data generated. Fragmentation of Data can be done in two ways:
- Vertical Fragmentation: Tables are split into rows so that each partition has some tuples of rows of the data.
- Horizontal Fragmentation: Tables are split into columns so that each partition becomes a smaller table or schema. The smaller tables must have a common candidate key to assure the lossless join.
Advantages of Distributed Database in DBMS
- Cost: If the data is stored at the site where it is mostly used, the cost of accessing it can be minimized. This is not possible in the centralized DBMS.
- Easy to Extend: If there is a need to expand the Database System, then adding the required number of sites(computers) is sufficient in DDBMS. But, Centralized DBMS requires huge efforts.
- Response Time: If data requested by the user is stored in the local system itself, the response will be faster.
- Fault Tolerance: If one of the systems suffers failure, the remaining sites of the Distributed Database System can generate the response for the user. But, in Centralized DBMS if the system fails, the entire system comes to a halt and no response is generated.
Mark Lesson Complete (Deep Understanding of Distributed Database in DBMS)
Mark Complete
Bookmark