What are Keys in DBMS?
Introduction
The modern database system which is also called Database Management System offers many advantages over the traditional file storage system such as an improved level of abstraction, a more secure database, and faster data access. Also, the concept of data modeling plays a critical role in designing the database. The main objective of data models is to uniquely identify the data objects which are also called the Entities and Keys allow us to do this.
Keys in DBMS are the attributes or sets of attributes that are used to uniquely identify the object in the database. They are also used to establish the relationship between one or more entities in the database. For example, the following diagram shows a ‘Customer’ table (the entity) in which the attribute Customer ID is used to uniquely identify the customers. Thus, it is a key.
Types of Keys
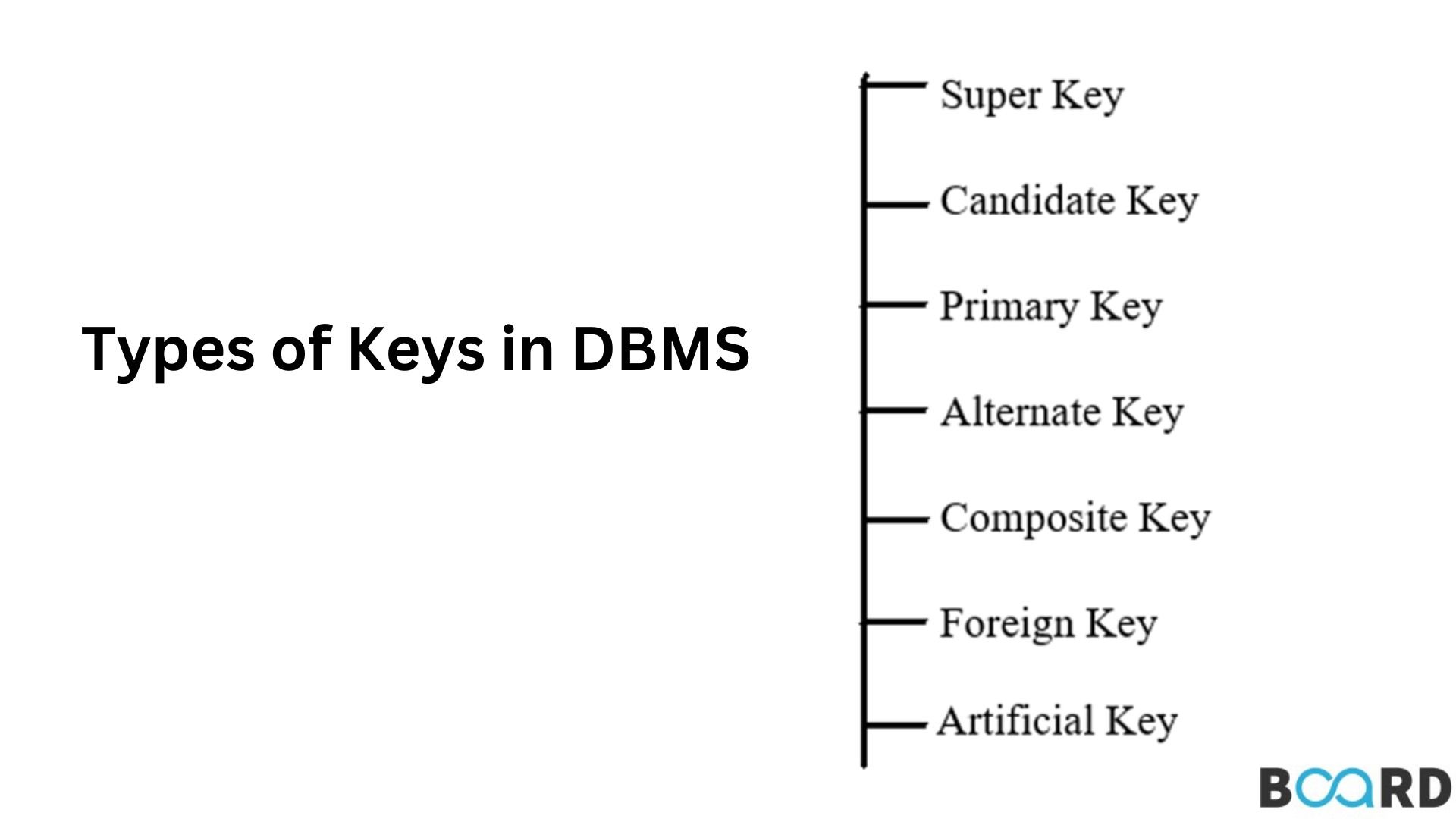
Keys are of different types depending upon which set of attributes are being used to identify the object. The above diagram shows the hierarchy of the Keys in DBMS. Types of Keys used in the Modern Relational Database Management System are:
- Super Key
Super Key is a set of all attributes that can be used to identify a row in a table. This key is the superset of the Candidate Key. It may contain null values. Super Keys in DBMS can have single or multiple attributes.
- Candidate Key
It is the set of attributes that can be used to uniquely identify a row (also termed a tuple). It always has unique values but it may contain null values.
- Primary Key
It is used to uniquely identify the row and cannot contain duplicate and null values. It is always unique and not null for a table. Also, there can be more than one primary key for a table.
- Alternate Key
Since Candidate Keys are always unique, a Candidate Key with not-null values can be declared as a Primary Key. In that case, other than the candidate key which has been declared as primary, the remaining keys are called the Alternate Keys in DBMS.
- Composite Key
Sometimes a single attribute is not sufficient to uniquely identify the row or tuple. Thus, more than one attribute is used to identify the tuple. It is called Composite Key.
- Foreign Key
Foreign Key is the column (attribute) of a table that is used to uniquely identify the rows of another table. Thus, when an attribute of one table acts as a Primary Key for another table, it is termed a Foreign Key.
- Artificial Key
An artificial Key is an extra attribute added to the table when the primary key is large and complex.
Now, let’s understand the different types of Keys using real-world examples. Suppose there is a table in the database which is named Customer.
Practical Example
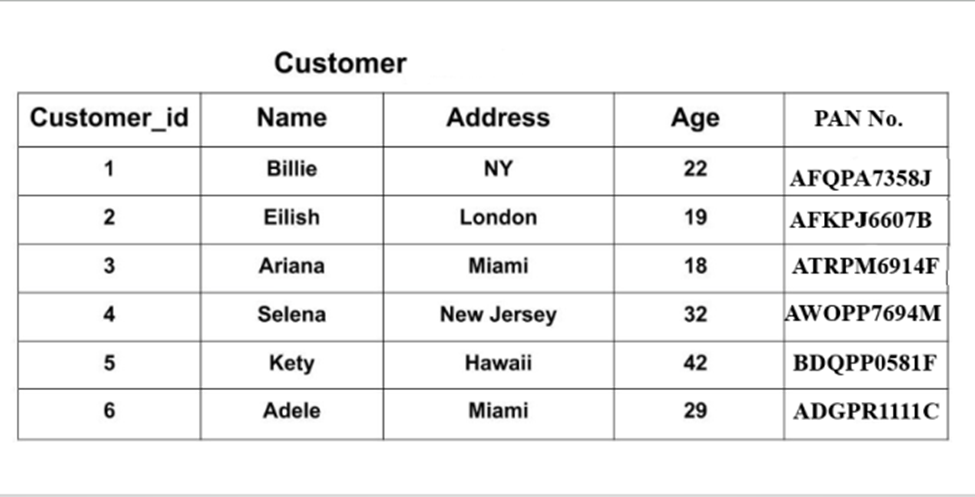
In the above table, the examples of the various Keys are given below:
- Super Key: Following super keys in DBMS can be declared for the above table:
1. Customer ID and Address
2. Customer ID and Name
3. Customer ID, Name, and Age
4. Name, Age and PAN No. etc.
- Candidate Key: Since names. Age and address may contain a duplicate value, we can have the following candidate keys:
1. Customer ID
2. PAN No.
3. Customer ID + PAN No.
- Primary Key: Out of all Candidate Keys, One Key can be declared as the Primary Key. Let us Declare Customer ID as the Primary Key.
- Alternate Key: Among the Candidate Keys, keys other than the Primary Key are Alternate Keys. Here, PAN No. acts as an Alternate Key.
- Composite Key: Suppose two numbers have the same name, then the name cannot be a primary key. But, Name+PAN No. is always unique for every customer. If Name+PAN No. is used as the Primary Key, it is the Composite Key for the table.
- Foreign Key: Suppose there is another table named ‘Travel_Details.’ And from that table, if the Passport ID Corresponding to names in the ‘Customer’ table is used as the ‘Primary Key’ in the Customer Table, then the Passport ID will be Foreign Key for Customer Table
- Artificial Key: If Name+PAN No. is used as a Primary Key, then it will be complex to use a such primary key. Thus, a new attribute called ‘Row_Id’ can be assigned as the Primary Key. It doesn’t exist in the database but it can be used to make the process simpler.
Therefore, the above Keys in DBMS are used to uniquely identify the rows or tuples in the table.
Mark Lesson Complete (What are Keys in DBMS?)
Mark Complete
Bookmark