Indexing in DBMS
Introduction
Have you heard anything like indexing in DBMS? If not, then don't worry. Board Infinity got your back.
In this article, we will discuss indexing in DBMS and how it can be useful to us in DBMS. We will discuss its types and what are their properties. So basically, data structures are used in the DBMS indexing technique to reduce the time a database query needs to search. It facilitates quick data retrieval from the database and faster query results. Database performance is improved by indexing. Furthermore, it uses less room in the main memory. Before moving forward, let us understand what indexing is.
Indexing in DBMS: What is It?
To easily access certain data from the database, indexing is utilized. Indexing is a method for reducing the time a database query takes to search through data by using data structures. By building an index table internally, indexing decreases the number of discs needed to access a specific piece of data. A table or index is created to do indexing.
Two columns that are a key-value pair make up an index's typical structure. Selected columns from the tabular data of the database are duplicated in the two columns of the index table or the key-value pair. Let us understand the structure of the index.

The database table's Primary Key or Candidate Key is duplicated in the Search Key in this case. Standard practice dictates that we sort the Primary or Candidate keys we have chosen to store to speed up searches or queries.
A group of pointers in the data reference holds the address of the disc block. The data referred to by the Search Key is found in the pointed disc block. Because it employs block-based addressing, Data Reference is also known as Block Pointer. Let us understand the indexing characteristics in DBMS.
Indexing Characteristics
The indexing has several characteristics:
- Access Types: This is a term that describes the several types of access, including value-based search, range access, etc.
- Access Time: The time required to locate a specific data element or group of elements is referred to as access time.
- Insertion Time: This term describes the time required to locate the right space and enter new data.
- Deletion Time: Time required for both updating the index structure and finding and deleting an item.
- Space Overhead: This phrase refers to the extra room needed for the index.
Storing the Data
The indexing methods for storing the data typically use one of two types of file organization mechanisms:
1. Sequential File Organization another name for this is Ordered Index File
2. Hash File organization
Let us discuss them one by one.
Sequential File Organization
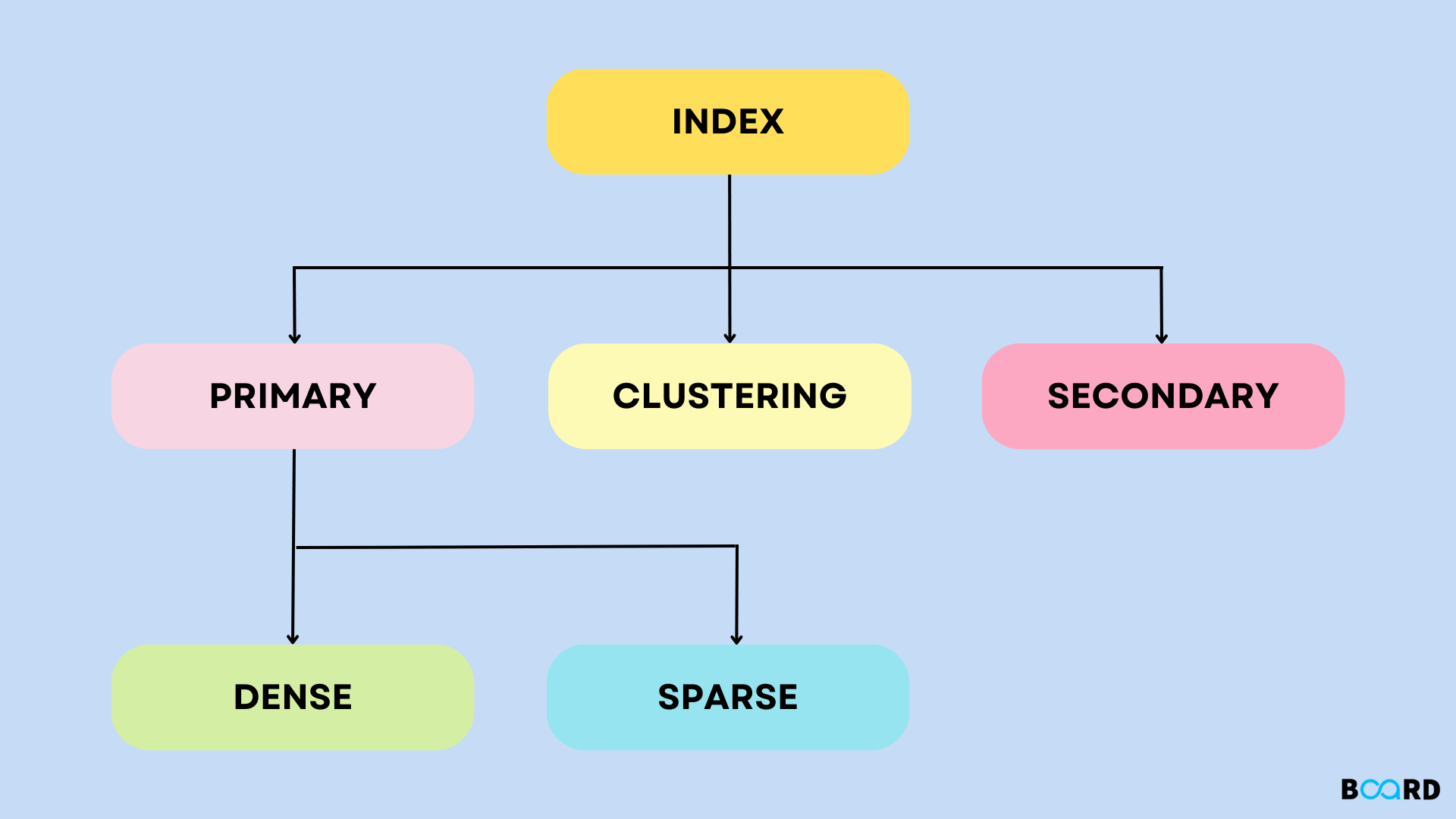
The indices in this are based on the values being sorted in order. These are a more common and speedy type of storing mechanism. These ordered or sequential file structures could store the data in either a sparse or dense format:
- Sparse Index: Only a few entries in the data file have an index record. We find the index record with the greatest search key value that is less than or equal to(≤) the search key value that we are looking for to find a record. Starting with the record that the index record points to, we move forward (sequentially) using the pointers in the file until we locate the requested record. The needed number of accesses is log2(n)+1, where n is the number of blocks acquired by the index file.
- Dense Index: There is an index record for each search key value in the data file. The first data record with that search key value is referenced in this record, which also includes the search key itself.
Hash File organization
Indices rely on the values being evenly distributed across several buckets. A hash function is a function that decides which buckets to assign values.
The three main indexing techniques are as follows:
- Clustered Indexing: A clustering index is defined on an ordered data file. On a non-key field, the data file is arranged. The index may occasionally be built using columns other than the primary key, which may be unique for some entries. In these situations, grouping two or more columns together to obtain the unique values and creating an index can help us locate the records more quickly. The clustering index is the technique in question. In essence, groups of records are formed for them, and indexes are then made for these groupings.
- Non-Clustered or Secondary Indexing: A non-clustered index simply provides a list of virtual pointers or references to the location where the data is stored, i.e., it does not attempt to cluster the data. Data is not physically kept in the index order. Instead, leaf nodes contain the data.
- Multilevel Indexing: Indicators expand along with the size of the database. A single-level index may grow to an unmanageable size with multiple disc accesses as it is kept in the main memory. To enable storage of the same information in a single block, the multilevel indexing divides the main block into numerous smaller blocks. The inner blocks of the outer blocks are further divided into data blocks that are pointed to by the outer blocks. Fewer overheads make it simple to store this in the main memory.
Conclusion
Indexing is a method for reducing the amount of time a database query needs to search. Search Key and Data Pointer or Reference are the two columns in the index table. Ordered, Single-level and Multi-level indexing are the three types available. Three categories of single-level indexing exist: primary, secondary, and clustered. Primary single-level indexing uses primary keys; secondary single-level indexing uses candidate keys.
There are two categories of ordered indexing: dense (each search key value in the database has a record in the index table) and sparse. Data pointers are stored in B+ Trees for multi-level indexing. Indexing facilitates more effective performance and quicker data retrieval.
Mark Lesson Complete (Indexing in DBMS)
Mark Complete
Bookmark