Apriori Algorithm

Introduction
You will discover all there is to know about the Apriori algorithm in this post. In basket analysis, the Apriori method is regarded as the fundamental algorithm. Basket analysis is the examination of a customer's shopping cart.
The objective is to identify frequent itemsets—combinations of products that are frequently purchased together. The domain is referred to by its technical name, frequent itemset mining.
When we employ frequent item sets and the Apriori method, basket analysis is not the only sort of analysis that can be performed. Theoretically, you could use it to examine frequent item sets for any subject.
Apriori assumes that:
The Apriori algorithm's steps
Example:
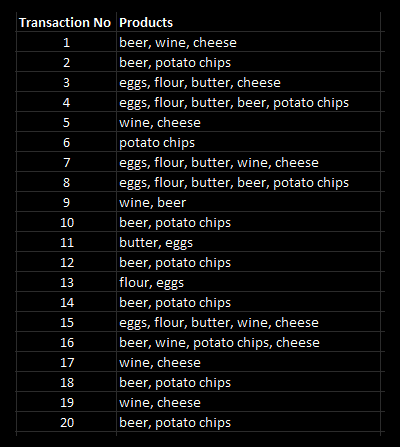
Step 1:
Calculating each individual item's support
- Support is the foundation of the algorithm. The support is simply the volume of transactions for a particular product (or product combination).
- The computation of each item's support is carried out as the algorithm's initial step. Counting the number of transactions that occur for each product is really all there is to it.
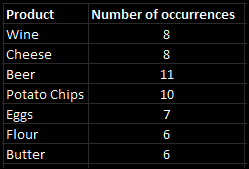
STEP 2: Choosing the support threshold
We will use the support information we have for each specific product to eliminate some of the less common ones. To do this, we must choose a support threshold. Let's pick 7 as the minimum in the example we're using right now.
STEP 3: Selecting the frequent items
It is clear that two separate goods each have a support rating of under 7. (meaning that they have less than 7 occurrences). Butter and Flour are those goods.
Unfortunately, flour and butter will not be taken into account in the following stages.
STEP 4: Obtaining the assistance of the regular item sets
The Apriori algorithm's great "innovation" is that all pairs that contain any of the uncommon components will be outright disregarded. We now have a lot fewer item pairs to scan as a result of this.
The list of all the pairs that include either Butter, Flour, or both are shown below. These can all be thrown away, which will hasten the process of conducting our counts.
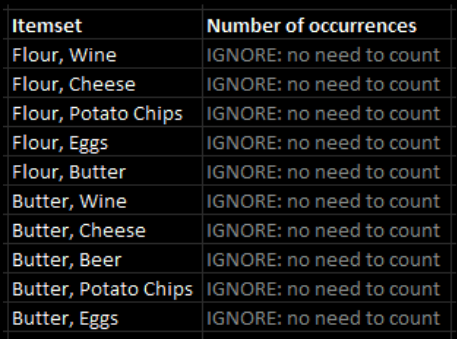
In this example, there are still a few combinations that must be counted:
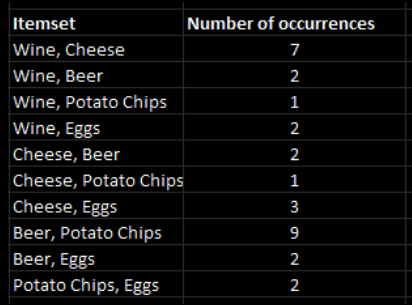
As you can see, just two product pairings remain that are above support at this time: wine and cheese and beer and potato chips.
STEP 5: Repeat for more substantial sets
Now let's do the same for the sets that include three products. As before, we won't score any sets that the prior phase had already eliminated.
The other couples were:
Potato chips, beer, cheese, and wine
STEP 6: Create association rules and confidence calculations.
There are no triplets without at least one uncommon pair. This indicates that the pairs of Wine, Cheese, and Beer, Potato Chips have been selected as the most popular combos.
The subsequent stage is to transform the largest frequent itemsets into Association Rules. Association Rules go beyond merely naming products that commonly appear together.
The format of association rules is Product X => Product Y. In other words, you get a rule that says you are likely to buy product Y if you purchase product X.
A further metric called confidence exists. A percentage of circumstances in which this rule is applicable is indicated by confidence. If there is 100% confidence, then this relationship always happens; if there is 50% confidence, then the rule only applies half the time.
STEP 7: Calculate the Lift
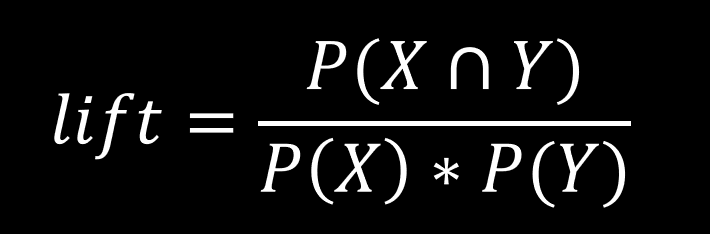
- The products are independent of one another if the lift of a rule is 1. Any rule with a lift of 1 is revocable.
- A rule's lift value, which is greater than 1, indicates how strongly the right-side product depends on the left side.
Conclusion
In conclusion, you have discovered a foundational algorithm in frequent itemset mining called the Apriori algorithm.