Directed Acyclic Graph: Representation
Introduction
The compiler's code is an object code for a specific low-level programming language, like assembly. We've seen how lower-level object code is produced by converting source code written in a higher-level language into a lower-level language. Lower-level object code must contain the following minimal characteristics:
- It ought to convey the source code's actual meaning.
- It ought to be effective in terms of CPU consumption and memory management.
- We will now examine how the target object code is created from the intermediate code (assembly code, in this case).
Here's how to understand DAG:
- Identifiers, names, or constants are represented by leaf nodes.
- Operators are shown as interior nodes.
- Interior nodes also indicate the outcomes of expressions or the names or identifiers that will be used to assign or store data.
Construction of D.A.G
Rule: 1
- With a DAG, The operators are always represented by inside nodes.
- The names, identifiers, or constants are always represented by exterior nodes (leaf nodes).
Rule: 2
During the DAG's construction,
- The existence of any nodes with the same value is checked.
- Only when no other node with the same value already exists is a new node generated. This process assists in finding common sub-expressions and preventing their re-computation.
Rule: 3
- The x:=y assignment instructions are not followed unless absolutely essential.
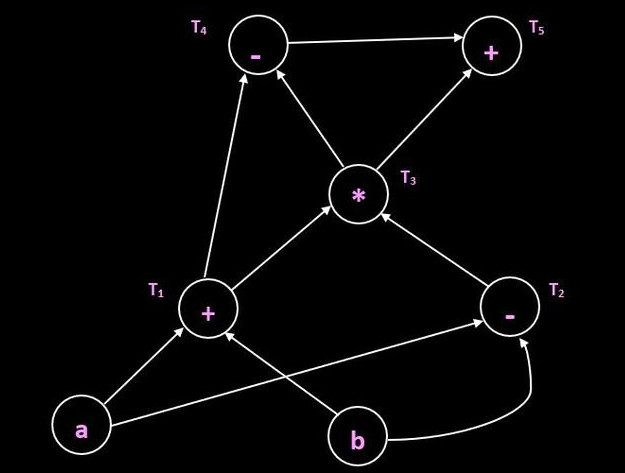
Example 1
Graph:
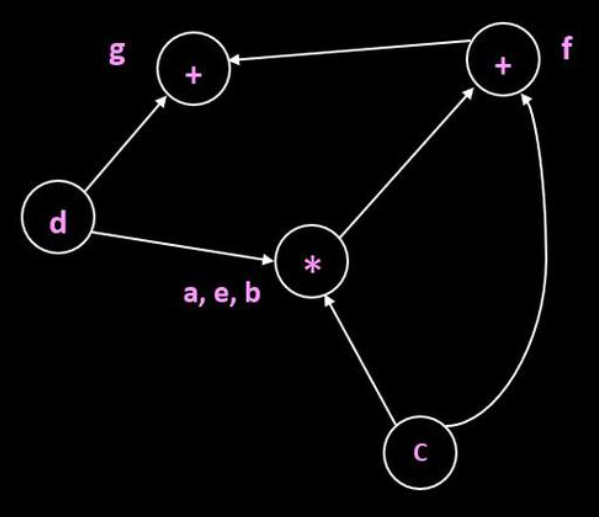
Example 2
Graph:
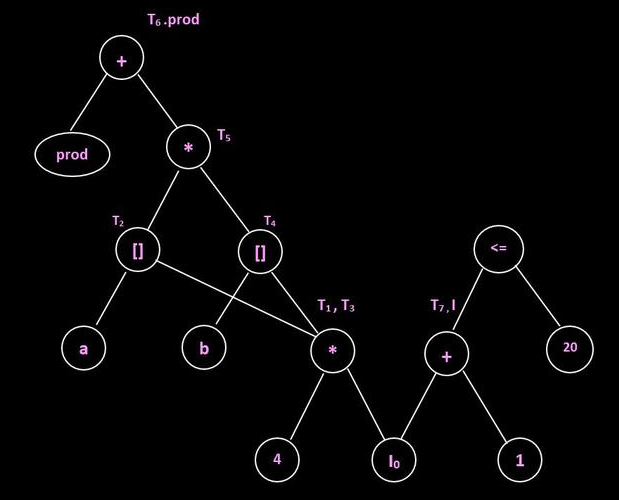
Example 3
Graph:
Applications of DAG
The representation of a wide range of flows, including data processing flows, is facilitated by DAGs. One can more easily organize the different phases and the accompanying order for these jobs by thinking about large-scale processing processes in terms of DAGs.
- In various contexts for processing data, the data is subjected to a number of computations to get it ready for one or more final destinations. The term "data pipeline" is frequently used to describe this kind of data processing flow. For instance, sales transaction data may be processed instantly so that it can be used to generate suggestions for customers in real time.
- The data can go through a variety of processes as part of the processing lifecycle, such as cleansing (fixing inaccurate or erroneous data), aggregation (calculating summaries), enrichment (finding connections with other pertinent data), and transformation.
Mark Lesson Complete (Directed Acyclic Graph: Representation)
Mark Complete
Bookmark